The premiere source of truth powering network automation. Open and extensible, trusted by thousands.
NetBox is now available as a managed cloud solution! Stop worrying about your tooling and get back to building networks.
Understanding EIGRP Queries
By stretch | Monday, March 22, 2010 at 4:13 a.m. UTC
Despite claims that EIGRP is a "hybrid" routing protocol, it is in fact a distance-vector routing protocol (Cisco has more recently ceded to using the term "advanced distance vector" in place of "hybrid"). A prime example of this behavior can be observed by examining EIGRP's route querying process. Queries are used to ask neighbors whether they have a path to a route which was recently lost. This is in contrast to a link-state routing protocol, wherein every router already has a complete picture (SPF tree) of its link-state area.
EIGRP's query process is simple in concept, yet can appear complicated when observed in operation on a live network. To better understand the query process, we'll examine what happens when the primary Internet uplink is lost in the topology below.
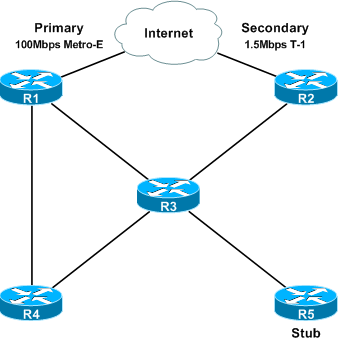
Under normal conditions, R1 has the primary uplink toward the Internet and redistributes a static default route (0.0.0.0/0) into EIGRP. R2 has a back-up Internet uplink, which is redistributed into EIGRP with a much higher (less favorable) metric than that of R1's as it should only be used when the uplink through R1 is down. Because the metric for this route is so high, it does not qualify as a feasible successor on any neighbor. Also, note that R5 has been configured as a stub router as it has only one path to the rest of the network.
While I've attempted to break the process down into logical steps or phases, the reader should be aware that queries and replies and handled independently on each router as they are received, without regard to the state of neighbors. Additionally, although it seems very drawn-out here, the entire process takes less than second to fully converge as tested.
This packet capture contains all EIGRP traffic sent across all five EIGRP links during convergence. Readers are encouraged to follow along in the capture as they read.
Step 1
R1's uplink to the Internet fails, and it loses its route for 0.0.0.0/0. R1 sends a query to each of its neighbors asking for a route to 0.0.0.0/0. R3 and R4 each send an acknowledgment to confirm that they received the query.
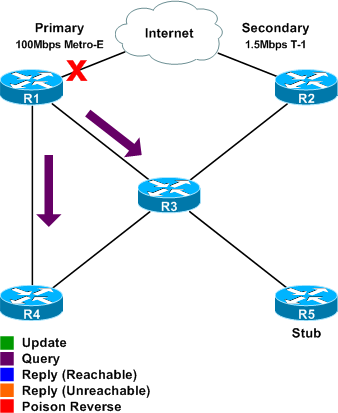
Because the queries were received from the successor for the route (indicating that the route is no longer valid) and there is no feasible successor, R3 and R4 both discard their route for 0.0.0.0/0 through R1.
Step 2
R3 and R4 both relay the queries to all of their neighbors. R3 queries R2 and R4 (but not R5, because R5 is a stub router). R4 queries R3.
Note that the exchange of queries between R3 and R4, although redundant, is necessary as no single router understands the overall topology beyond its own connected neighbors (a limitation inherent to distance-vector routing).
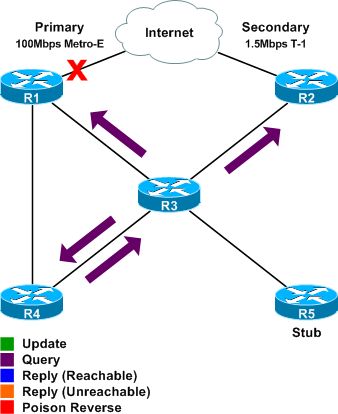
Notice that a query is also made from R3 to R1 at this point (packet #24). This appears to be the result of R3 processing the query from R4 slightly quicker than the query from R1, for whatever reason. This query is extraneous and unnecessary, but included here for the benefit of people following along with the provided packet capture. R4 does not relay to R1 the query it receives from R3.
Step 3
Next, we can see all the routers reply to the queries they received. R3 informs R4 it has no route for 0.0.0.0/0, and R4 informs R3 it has no route either. R1 replies to R3 that it (obviously) has no route as well. R2, however, does have a route to 0.0.0.0/0, it's uplink to the Internet. This reply is visible in packet #28 of the capture.
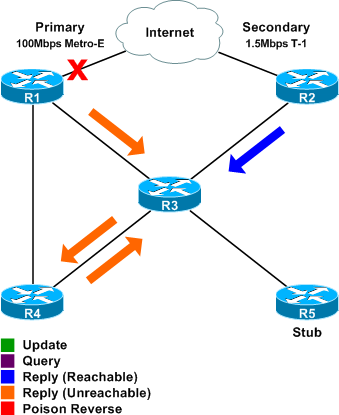
The only two outstanding queries (those which have not yet been answered) at this point are the two original queries from R1 to R3 and R4.
Step 4
R3 has a learned of a new path to 0.0.0.0/0 from the reply sent by R2. First, it sends a poison reverse update to R2 for this route. Second, it answers the original query from R1 with the new path to 0.0.0.0/0. Finally, it sends a normal update to all of its neighbors (other than R2) informing them of the new default route via R2.
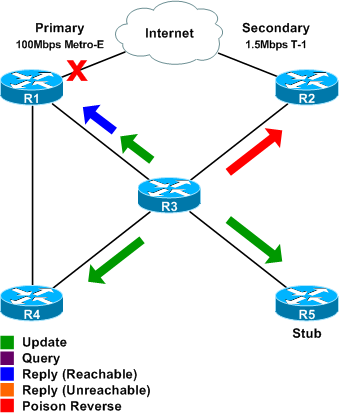
Step 5
After having learned of the new route via R3, R4 also sends a reply and update to R1. At this point, all queries have been answered.
R1 and R4 both send a poison reverse for 0.0.0.0/0 to R3 in response to the updates.
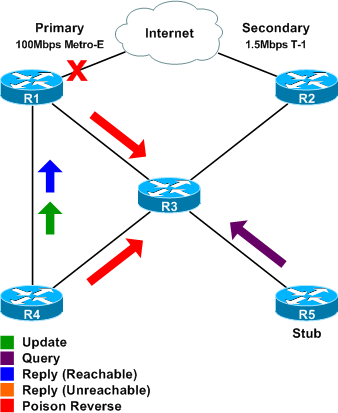
Now, just as we thought the network was about to settle down, we see a new query from R5, the stub router. The query is for the new 0.0.0.0/0 route which R5 just learned from R3. (Remember that stub routers should not receive queries, but they are free to send them.)
I could not find any documentation concerning this phenomenon, although it appears to serve in place of a normal poison reverse update (since stub routers generally may not send updates). If anyone can shed some light on this, I'd be happy to hear it.
Step 6
To wrap things up, R1 sends an update (_not_ a poison reverse) to R4 indicating that it to now has a path to 0.0.0.0/0. R3 responds to R5's query with a reply indicating the route to 0.0.0.0/0 is as previously advertised.
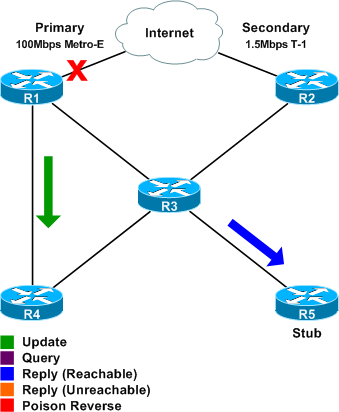
As you can see in the packet capture, the elapsed time from the first query to the final acknowledgment is only about 850ms (and that's in a lab using emulated routers).
Posted in Routing
Comments
March 22, 2010 at 7:48 a.m. UTC
This is beautiful, thank you!
March 22, 2010 at 4:35 p.m. UTC
Excellent run-down of the process. Quick question though - is the query process always initiated when a route is lost ? I have a 200-node EIGRP network and I can imagine how a flapping link might cause havoc :|
March 22, 2010 at 5:17 p.m. UTC
stretch, how much traffic did all this account in total?
March 22, 2010 at 6:51 p.m. UTC
@uscallesen: Yep, query storms suck.
@alvarezp: You can see in the attached capture file.
March 22, 2010 at 11:24 p.m. UTC
Hey Stretch, In the beginning of the article you mention that R1 "redistributes a static default route" but under Step 1 you mention "R1's uplink to the Internet fails, and it loses its route for 0.0.0.0/0"
Is R1 receiving the default route via the primary link or is it in fact statically defined on R1? If static, then how does R1 know to retract that route? IP SLA Tracking?
Thanks
March 23, 2010 at 1:01 a.m. UTC
@ekenny: When the next-hop interface transitions to the down state, the static route is nullified. Don't worry too much about why the route was retracted, as that detail is ultimately irrelevant to the query process.
March 23, 2010 at 4:07 p.m. UTC
If the secondary uplink router was injecting a route with a worse metric, why wouldn't it have been bumped up from feasible successor to successor when the primary route was withdrawn, thus saving you the routing update? I know this is a one-off from the intent of the post, but if a second route to the internet, presumably a default, existed in the topology table you only would have had to recompute when the primary default came back.
March 23, 2010 at 4:52 p.m. UTC
ekaleido, it was the goal of this topic to show u how the querying process is happening, not how to avoid it. The secondary link did not qualify for a feasible successor by purpose ;)
March 25, 2010 at 10:10 a.m. UTC
Stretch, you mention that you are capturing packets through emulated routers. I assume dynamips? If that's the case, how are you capturing the packets? I've yet to find a way to do this in my dynamips setup
March 25, 2010 at 6:01 p.m. UTC
@mellowd: I use GNS3, it's very convenient.
March 25, 2010 at 6:24 p.m. UTC
@Didzis, I understand what the post was trying to do but it also misrepresented that this type of process occurs everytime ANY route leaves the routing table, which is simply untrue in cases where there are feasible successors.
March 26, 2010 at 8:20 a.m. UTC
Hey Stretch - I have a q on poison reverse that I hope you can clarify. In Step 4 it's stated "R3 has a learned of a new path to 0.0.0.0/0 from the reply sent by R2. First, it sends a poison reverse update to R2 for this route".
Why does R3 send a poison reverse to R2 for the route it just learned from R2 (the new internet uplink route). The new internet uplink route should be a brand new route to R3. Is R3 poisoning the old 0.0.0.0/0 route through R1 that it advertised to R2?
That's kinda lost me...!
August 9, 2010 at 10:39 a.m. UTC
Can ip sla tracking help reduce the steps in the query process?
February 7, 2011 at 9:22 a.m. UTC
Thank you! very helpful to enlight the query process with "unexpected" issues included.
January 6, 2012 at 4:38 a.m. UTC
Thank you for your wonderful explanation
January 20, 2012 at 3:24 a.m. UTC
Hi !
I have a question , why R3 has to send a poison reverse update to R2 ?
February 6, 2012 at 5:10 p.m. UTC
Hi,
That is a really nice article on the EIGRP query process. It demonstrate perfectly why a stub router should not be used a transit router as that could cause a routing loop. EIGRP use the query process to withdraw routes and as EIGRP stub will not receive query that could be an issue.
/Aitaseller
February 18, 2012 at 10:49 p.m. UTC
Hi,
Great thanks for the example, it is quite helpful to understand the Query mechanism.
But I couldn't understand the existence of the "Reply (Unreachable)" message in Step 3, sent from R3 to R4. As far as I understand, a router needs to wait for replies to all of its relayed queries, before replying to the originating Query. In this case, R3 hasn't received the reply from R2 yet. So how can R3 send the "Reply (Unreachable)" message?
Thanks,
Onur
August 7, 2012 at 7:13 p.m. UTC
Regarding R5's behavior in step 5...
As R5 is a stub router, the R3 did not send it a Query in step 2. That means that in step 4 R5 still believes that it can get to 0.0.0.0/0 via R3 - USING THE OLD METRIC. More specifically, R5 has its feasible distance and R3's distance to 0.0.0.0/0 based on static route from R1.
When R3 sends the Update with new metric to 0.0.0.0/0 in step 4, the R5 recalculates the new distance from R3 to the 0.0.0.0/0 and concludes that the R3 does not satisfy the feasibility condition anymore, as R3's new distance to 0.0.0.0/0 is higher than R5's current feasibility distance (never mind that FD is based on an old report from R3!).
So R5 removes R3 from the list of feasible successors for 0.0.0.0/0 and checks if there is another one. Nope, R3 was the only one. So the R5 goes active on this particular route, puts FD to infinity, and sends Query to all the neighbors (all = just R3).
The R3 sends a Reply (with the same metric as in the Update it sent a moment ago), but now the metric that R3 provides is better than the current one (infinity), so R5 accepts R3 as the successor.
November 29, 2012 at 5:48 p.m. UTC
Amazing post strech. Really helps to understand the query process
@mostlynetworking - thanks for pointing that.
I'm still having hard time to understand why R3 really sends posion reverse to R2?..
November 29, 2012 at 6:10 p.m. UTC
I think I've figured it out why R3 is posining reverse R2:
When R3 receives the route update for 0.0.0.0 from R2 and installing it in its routing table, its poisoning reverse R2 to make sure R2 route to 0.0.0.0 is not through R3. R2 receives the update, and since it has a better route to 0.0.0.0 it just discards it. Now if R2 0.0.0.0 route was pointing to R3, without the poison reverse mechanism we were ending with a routing loop between R2 and R3.
January 29, 2013 at 5:20 p.m. UTC
Such a nice picture explanation. Awesome for review.
April 29, 2013 at 4:31 p.m. UTC
Nice explanation, very well illustrated. Excellent work.
May 8, 2013 at 11:57 a.m. UTC
Good stuff! Nice one guys...
July 20, 2013 at 7:23 p.m. UTC
Thank you, man! Great work!
February 17, 2014 at 8:23 a.m. UTC
Here is the reason, "why R3 will send poison reverse to R2 after learning about 0.0.0.0/0 from R2."
Poison reverse is another way of avoiding routing loops. Its rule states:
"Once you learn of a route through an interface, advertise it as unreachable back through that same interface."
When R3 learns about 0.0.0.0/0 from R2, it advertises 0.0.0.0/0 as unreachable through its link to R2. R2, if it shows any path to Network 0.0.0.0/0 through R3, removes that path because of the unreachable advertisement. EIGRP uses split horizon and poison reverse to help prevent routing loops.
August 30, 2014 at 7:17 a.m. UTC
@Mo -> According to what I've learned from reading and analyzing, POISON REVERSE contain a message that says, "YOU ARE MY WAY TO GO TO MY DESTINATION" to avoid confusion and loop into the network.
@Stretch -> Thank you sir for this post, additional knowledge added to my list!
December 13, 2015 at 8:43 p.m. UTC
this is great but it would be easier to follow if we knew what IP's were assigned to each router.
September 28, 2016 at 6:53 a.m. UTC
@robert -> It is very easy to find. In this topology subnet 10.0.x.y is used. "x" indicates link between routers (for example: 13 is a link between R1 and R3) and "y" is actual router's number.