The premiere source of truth powering network automation. Open and extensible, trusted by thousands.
NetBox is now available as a managed cloud solution! Stop worrying about your tooling and get back to building networks.
Distance vector versus link-state
By stretch | Thursday, October 2, 2008 at 3:36 a.m. UTC
There are two major classes of routing protocol: distance vector and link-state. It's easy to remember which protocols belong to either class, but comprehending the differences between the two classes takes a bit more effort.
Distance vector routing is so named because it involves two factors: the distance, or metric, of a destination, and the vector, or direction to take to get there. Routing information is only exchanged between directly connected neighbors. This means a router knows from which neighbor a route was learned, but it does not know where that neighbor learned the route; a router can't see beyond its own neighbors. This aspect of distance vector routing is sometimes referred to as "routing by rumor." Measures like split horizon and poison reverse are employed to avoid routing loops.
Link-state routing, in contrast, requires that all routers know about the paths reachable by all other routers in the network. Link-state information is flooded throughout the link-state domain (an area in OSPF or IS-IS) to ensure all routers posses a synchronized copy of the area's link-state database. From this common database, each router constructs its own relative shortest-path tree, with itself as the root, for all known routes.
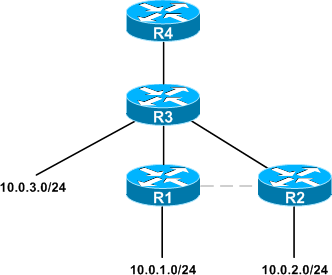
Consider the following topology.
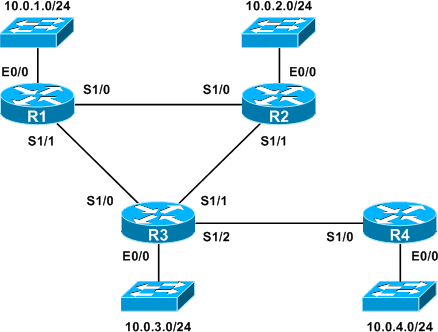
Both distance vector and link-state routing protocols are suitable for deployment on this network, but each will go about propagating routes in a different manner.
Distance Vector
If we were to run a distance vector routing protocol like RIP or EIGRP on this topology, here's how R1 would see the network, assuming each link has a metric of 1 (locally connected routes have been omitted):
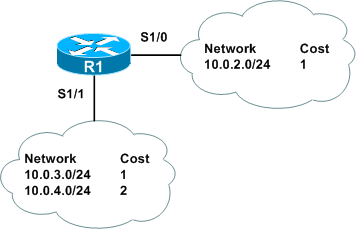
Notice that although R1 has connectivity to all subnets, it has no knowledge of the network's structure beyond its own links. R4 has even less insight:
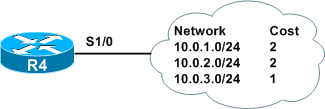
Because they do not require routers to maintain the state of all links in the network, distance vector protocols typically consume less overhead at the expense of limited visibility. Because routers have only a limited view of the network, tools like split horizon and poision reverse are needed to prevent routing loops.
Link-State
Now, let's look at the same topology running a link-state routing protocol (in a single area). Because each router records the state of all links in the area, each router can construct a shortest-path tree from itself to all known destinations. Here's what R1's tree would look like:
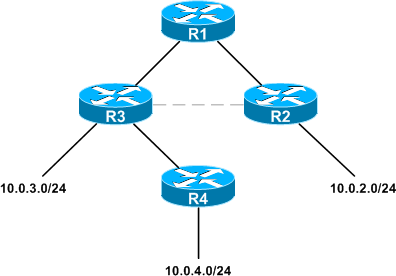
R4 has constructed its own shortest-path tree, different from that of R1:
Although maintaining link-state information for the entire area typically requires more overhead than does processing advertisements only from direct neighbors, but provide more robust operation and scalability.
Posted in Routing
Comments
October 2, 2008 at 9:02 a.m. UTC
I remember when we had to count out excersises using Dijkstra-algorithm at college years ago. On a piece of paper..another useless thing I tought, and just realized OSPF uses the same math to build the shortest-path tree.
October 2, 2008 at 11:30 a.m. UTC
As usual neat & clear write-up. +1 to your fan's list :-)
October 2, 2008 at 2:27 p.m. UTC
It's funny how even some link-state protocols still act like link-state in certain scenarios.
October 2, 2008 at 6:53 p.m. UTC
Nice information. Thanks. I like to add one more point. If a network is huge its better to use link state than distance vector,because there are more limitations in distance vector like Hop count limit etc
October 2, 2008 at 10:44 p.m. UTC
A 'vector' has both direction and distance already. So then why did they call it 'distance vector'? Those crazy network guys..
October 18, 2008 at 10:16 a.m. UTC
I like the blog theme :p
January 27, 2009 at 7:43 p.m. UTC
Thank you!
This helped a lot, better than my teachers pdf´s, and all he had to do was translate the cisco notes.
anyways... as said above, very clear & neat
April 11, 2009 at 2:25 p.m. UTC
it is a boon for the learner........thanks a lot
April 21, 2009 at 2:10 p.m. UTC
never came across a definitive explanation untill now! More grease to your elbow... Thanks!
May 3, 2009 at 3:56 a.m. UTC
QUOTE " Venkatesan commented on 2 Oct 2008 at 6:53 p.m.
Nice information. Thanks. I like to add one more point. If a network is huge its better to use link state than distance vector,because there are more limitations in distance vector like Hop count limit etc"
The intuition seems appropriate at first glance but further investigation reveals that large networks are best supported using DV-centric approach instead of LS. Imagine a large network with 1000's of routers having to keep track of all the others.
Hence, it is clear why the networks of network - the Internet - adopts a path-vector approach in its usage of BGP.
June 19, 2009 at 10:06 a.m. UTC
I searched through google to understand the difference between link state and distance vector and out of all the sites I have reffered, this blog was the one which cleary helped me to understand the difference!! Thanks for providing the clarity!!
Cheers,
Arun
July 8, 2009 at 2:00 p.m. UTC
Clear and absorbed thanks for the day.
January 26, 2010 at 1:06 p.m. UTC
Good Explanation dude, brief and easy to understand!! Nice one!!
May 2, 2010 at 1:40 a.m. UTC
Good Information,
After seeing this difference. I think that its better to use Distance vector Routing for large networks. Because If a router uses Distance vector algo.. the router will come to know only the details of neighbouring router. But If a router uses Link state Routing then each router will find is own shortest path. I Think this not good for larger networks like (1000 routers).
This is my assumption. Any other guys you can clarify on this and please let me know, am I right?
July 2, 2010 at 7:24 p.m. UTC
@those of you speaking of DV vs LS for large networks, don't forget about AREAS. In OSPF the link states are only known within an area, outside of that OSPF acts like a DV protocol. Therefore, LS protocols are fine for large networks if designed properly.
August 16, 2010 at 3:12 p.m. UTC
Very nice, Very informative....
September 8, 2010 at 1:46 a.m. UTC
The information provided is really superb !
Thank you
December 5, 2010 at 10:11 p.m. UTC
nice post! thanks!
December 27, 2010 at 3:37 p.m. UTC
Its simple and easy to understand. It really help me a lot.
May 14, 2011 at 3:36 p.m. UTC
Its help me to understand the real difference,Thankyou!
August 9, 2011 at 7:57 p.m. UTC
Very nice explanation.
Raj
November 25, 2011 at 6:33 p.m. UTC
Very nice sharing & explanation....
I alwayz prefer internet 4 reading & understandin' rather than books :))
Thumbs Up
May 20, 2012 at 3:35 p.m. UTC
Very straight forward explanation....nice way to learn...rather than books..
May 30, 2012 at 5:00 a.m. UTC
nice article...clear and simple ...thanks....even i enjoyed the comments as well ...very logical people they are ..specially one who said vector already have distance and direction...for him i need to say..vector has magnitude and direction not magnitude always must not be distance....i think so.....for that reason protocol is named distance vector routing protocol...
September 5, 2012 at 1:45 p.m. UTC
Great article! Thank you!
November 19, 2012 at 8:59 a.m. UTC
vector refers to the array-like data structure, doesnt mean vector literally...
December 1, 2012 at 3:56 p.m. UTC
Best Notes on Distance & Link State Protocol,Very Clearly Understood
January 7, 2013 at 7:20 a.m. UTC
Thank you, Jeremy! You made it real simple for me.. :D
February 22, 2013 at 8:47 p.m. UTC
Very well explained. Thanks man!
November 8, 2013 at 4:11 p.m. UTC
Interesting!
Distance Vector creates the fastest path.
Link State creates the shortest path.
"R4 has constructed its own shortest-path tree, different from that of R1:"
The shortest path doesn't necessarily mean the fastest path.
It could be quicker to go (R4->R3->R2->R1), but we don't know that because there are no costs associated with link state.
I am going to come up with a Link State Distance Vector Protocol (LSDVP). (You heard it here first) Why not provide the best of both protocols? To optimize the route, it might not take the shortest path. All you would have to do is provide a distance vector along (Router path cost) with the link state protocol. Done.
CJH
April 2, 2014 at 12:32 p.m. UTC
I think vector actually refers to the arrays or table that DUAL uses when calculating possible paths to a destination.
Source: DUAL algorithm white paper
April 27, 2014 at 8:47 a.m. UTC
Great! Thank you!
May 9, 2014 at 9:58 p.m. UTC
Awesome explanation. Really good for people just learning this stuff. I wonder if the military would use Distance Vector....seems like too many router for Link State, but I am just learning so I can be wrong.
October 18, 2014 at 7:18 a.m. UTC
Thank you Jeremy, very easy and nice explanation. Much better than cisco books.
March 16, 2015 at 1:31 a.m. UTC
Thank you for very short and clear explanation
April 28, 2015 at 4:05 p.m. UTC
Great!!!!!!
July 22, 2015 at 6:37 p.m. UTC
Thanks for the explanation!!!
August 11, 2015 at 7:56 p.m. UTC
Scary how easy to understand this explanation was for me. Definitely helped me study for my CCENT exam.
September 5, 2015 at 6:45 p.m. UTC
thank you, wonderful explanation
May 18, 2016 at 1:35 p.m. UTC
very good i understand it now
August 18, 2016 at 8:49 a.m. UTC
Big interview.. brain going in t melt down.. cant remember simple concepts from years back.. thanks for making this short and clear.
August 18, 2016 at 8:02 p.m. UTC
Minor nit: I believe it's called "distance vector" because the magnitude may be measured in several dimensions, not just a scalar hop-count which RIP uses.
In EIGRP for example, link delay, minimum path bandwidth, reliability, utilization, path MTU, etc. are all reported to compute a complex vector measurement.