The premiere source of truth powering network automation. Open and extensible, trusted by thousands.
NetBox is now available as a managed cloud solution! Stop worrying about your tooling and get back to building networks.
MAC Address Aggregation and Translation as an Alternative to L2 Overlays
By stretch | Tuesday, November 18, 2014 at 2:05 a.m. UTC
Not so long ago, if you wanted to build a data center network, it was perfectly feasible to place your layer three edge on the top-of-rack switches and address each rack as its own subnet. You could leverage ECMP for simple load-sharing across uplinks to the aggregation layer. This made for an extremely efficient, easily managed data center network.
Then, server virtualization took off. Which was great, except now we had this requirement that a virtual machine might need to move from one rack to another. With our L3 edge resting at the top of the rack, this meant we'd need to re-address each VM as it was moved (which is apparently a big problem on the application side). So, now we have two options: We can either retract the L3 edge up a layer and have a giant L2 network spanning dozens of racks, or we could build a layer two overlay on top of our existing layer three infrastructure.
Most people opt for some form of the L2 overlay approach, because no one wants to maintain a flat L2 network with dozens or hundreds of thousands of end hosts, right? But why is that?
Challenges of a Layer Two Network
Layer two networks in the data center pose two major challenges. First, L2 networks must be free of forwarding loops. Traditionally this has been solved using some flavor of Spanning Tree to block all redundant paths, but this approach severely limits the amount of throughput available to each rack, as only one uplink (or LAG) can be active at a time. Other solutions to the loop problem include various multi-chassis LAG and virtual chassis implementations from different vendors. These each have their pros and cons and are better discussed elsewhere.
What I've been pondering lately is the second problem: MAC table size. Assuming you can solve the L2 loop problem reasonably well, you still have to worry about every switch learning every MAC address across the entire L2 domain. Most switches appropriate for a dense data center environment can handle 128 thousand or more MAC addresses, but a topology change (such as transitioning from an active uplink to a backup) might trigger a flush of nearly the entire table. The switch needs to re-learn thousands and thousands of MAC addresses as fast as it can, which might not be fast enough to avoid impacting network availability.
Why does this problem affect only L2 topologies, and not layer three designs? The key difference is that L3 endpoint addresses can be aggregated. A router doesn't need to know explicitly that the hosts at 192.0.2.36, 192.0.2.55, 192.0.2.187, and 192.0.2.208 are each reachable via a common interface. It only needs to know one route, for the 192.0.2.0/24 network. This function is inherent to IP addressing. MAC addresses, in contrast, can not be aggregated. Or can they?
MAC Aggregation
Historically, the problem with MAC addresses has been that they are both globally unique (mostly) and pseudo-random. It's extremely difficult, if not impossible, to predict the MAC address of each physical interface to be installed in each device in a data center, since each vendor has its own OUI(s) and the lower 24-bits of a MAC are effectively random.
It's very subtle, but the industry's shift to virtualization is actually solving this problem for us. When you create a virtual machine today, each of its network interfaces gets assigned one or more completely arbitrary MAC addresses by the hypervisor or by some central orchestration tool. For instance, VMware VMs typically use the OUI 00:50:56, with the lower 24-bits generated by some dynamic function. Unlike in the physical world, there's nothing preventing us from writing rules dictating what MAC addresses gets assigned to a VM.
Let's say we needed to deploy 100 racks with 10,000 VMs each in a single L2 domain. This would push us to the current limit of MAC table sizes on even the beefiest of switches (and we would need one or two of those beefy switches in every rack). But what if we decided to assign MAC addresses to each VM based on the physical location of its hypervisor? Assuming we use a privately-allocated 24-bit OUI (designated XX-XX-XX below), that leaves 24 bits of address space to carve up, which is analogous to a /8 prefix in IPv4. In our admittedly contrived scenario, we can simply designate the upper 8 bits as the rack identifier, and the lower 16 bits as the rack-specific VM identifier.

If our virtualization infrastructure is programmed to create VMs following this scheme, it allows us to aggregate at the L2 core. Instead of learning 1,000,000 individual MAC addresses, the core would only need to know 100 "MAC routes" (one /32 MAC route per rack). Each top-of-rack switch would still need to know the addresses of every VM interface in the rack, but at around 10 or 20 thousand MACs that's not problem. Each ToR switch would also need to maintain a "default" MAC route of 00-00-00-00-00-00/0 pointing northbound toward the core layer.
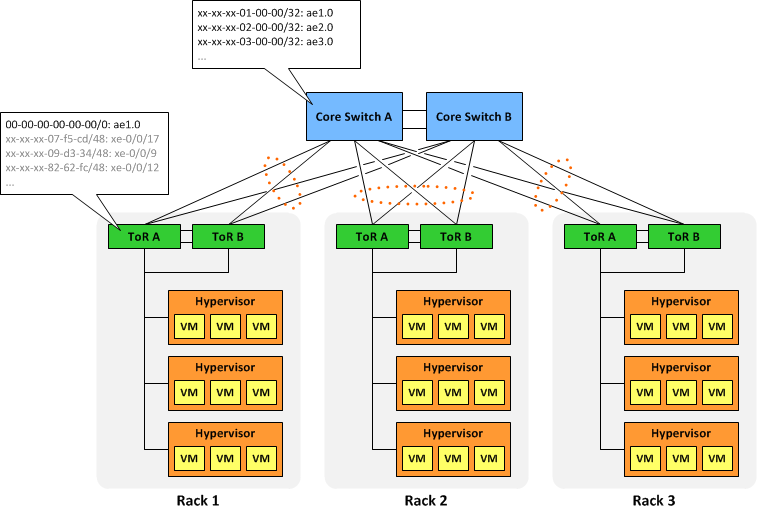
Of course, each MAC route would need to be installed within each VLAN in the domain, so the total number of aggregate routes would equate to the number of racks multiplied by the number of VLANs in use. That's still a tremendous savings over using individual host addresses.
If the necessary hardware support existed today, configuration syntax for a Juniper switch might look something like the snippet below. (These are not real commands.) Alternatively, it should be feasible to learn MAC aggregate routes dynamically via an extension to BGP or other routing protocol.
ethernet-switching-options {
static {
vlan 123 {
route xx:xx:xx:01:00:00/32 next-hop xe-0/0/0.0;
route xx:xx:xx:02:00:00/32 next-hop xe-0/0/1.0;
route xx:xx:xx:03:00:00/32 next-hop xe-0/0/2.0;
route xx:xx:xx:04:00:00/32 next-hop xe-0/0/3.0;
}
}
}
This concept scales well to the insertion of an aggregation layer between the ToR and core layers, too. Each aggregation switch would need to know only the summary MAC routes for the racks it feeds and a default MAC route toward the core.
MAC Address Translation
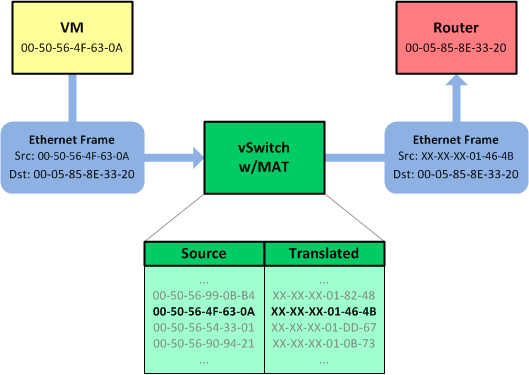
I know what you're thinking. "This is all just cupcakes and unicorns, but what happens when I need to move a VM to a different rack?" While perhaps less disruptive than changing the IP address of a VM, changing its MAC still requires some degree of modification to the VM's operating system (for example, Linux udev rules), which is best avoided. So instead of changing its MAC, we can simply translate it on the hypervisor.
Hang on, NAT is bad, right? Everyone knows that! The biggest sticking point with IP NAT is that it breaks end-to-end transparency: The IP address from which your traffic originates is not how the far end sees you (or vice versa). But at layer two, this isn't a concern. Do you know what the MAC address of the server at packetlife.net is? No, nor would you care. L2 addressing is significant only to the local link. Rewriting the source and/or destination MAC address on a frame as it passes between two L3 nodes has zero effect on its payload. (Remember, there's no encapsulation happening here.)
The ability to rewrite MAC addresses on the hypervisor simplifies our solution even further: VMs can be created with entirely random MAC addresses as they are today, and each hypervisor would simply MAT -- that's MAC Address Translation -- each "real" MAC to a MAC from its assigned pool (which is derived from its rack's aggregate).
Why Can't We do this Today?
Two features would be necessary to implement this crazy scheme today. First, we'd need the ability to perform one-to-one MAC address translation from an administratively defined pool on a hypervisor. This should be trivial to accomplish: We already have L3 NAPT in the hypervisor today. L2 translation is actually easier as it's completely stateless.
The second requirement is the primary barrier to adoption. As far as I'm aware, mainstream network hardware does not support longest prefix matching (LPM) for layer two addresses. LPM obviously has been around forever: It's how an IP router determines the best matching route for a destination address. But because MAC addresses have historically been considered unaggregatable, chipset manufacturers have understandably not built in this capability. That said, it should be perfectly feasible to include in future chipset iterations.
There are probably a number of caveats to this scheme that I haven't considered. I'm also not the first person to think of it, of course. But I do think the approach holds some merit, and it would at least be a pleasant departure from the industry's current approach of simply tunneling everything.
Please feel free to berate my theories and question my professional competence in the comments below as per established social convention.
Posted in Design
Comments
November 18, 2014 at 3:27 a.m. UTC
And here I was thinking layer 3 solutions like Cisco Overlay Transport Virualization were cool and you come up with this great notion. Gotta love networking, though it does mean that I have tell students "You know all those immutable rules about the OSI and TCP/IP models I told you about, well, ...." :-) cheers Aubrey
November 18, 2014 at 1:44 p.m. UTC
Why would you want complex MAC aggregation and MAC Address Translation if you could also use technologies like SPB (802.1aq), TRILL or FabricPath. The use of these technologies would reduce the complex administration of mac addresses...
November 18, 2014 at 2:21 p.m. UTC
@Derco: All of those are far more complex solutions than simple LPM and one-to-one adress translation, which we have been doing for decades. They also don't (as far as I'm aware) solve the problem of maintaining large MAC tables. Please correct me if I'm wrong.
MAC address translation would be entirely dynamic: You'd define pools administratively once, but the allocations within would all be automatic from then on, analogous to how you'd set up L3 NAT (without overloading) today.
November 18, 2014 at 10:26 p.m. UTC
How about a little MAC address translation on the switch side of things to keep legacy intact.
November 18, 2014 at 10:46 p.m. UTC
@Ewald: One aspect of this approach that I neglected to point out is that legacy host MAC switching continues to function exactly as it always has. Switches would still learn any individual MACs not covered by an aggregate route and install them into the MAC table.
November 19, 2014 at 1:29 p.m. UTC
It's posts like these that get me excited about the networking field. I gotta say I still read your blog (archive stuff, new stuff) just about every day, just the best written, most relatable networking blog on the internet!
November 19, 2014 at 2:58 p.m. UTC
Hey Jeremy, Interesting read! At first glance, you'd probably need two other pieces to make this work. 1) during a vMotion, something would need to move the MAT state to the new vSwitch. And 2) the MAT vSwitch would need to intercept ARP responses from the VMs and rewrite.
Cheers, Brad
November 19, 2014 at 11:49 p.m. UTC
@Brad: Good points.
1) There's no state to communicate among hypervisors when moving a VM. When a VM leaves its current hypervisor, the 1:1 mapping gets deleted and the "outside" MAC is returned to the free pool. On the new hypervisor, a new translation is created for each interface using the new local pool. At most, the new hypervisor would need to send a gratuitous ARP with the VM's new outside MAC.
2) Good point. ARP would need to be translated by the hypervisor in both directions. That should be trivial to implement though, unless I'm overlooking something, which is pretty likely.
November 20, 2014 at 1:18 a.m. UTC
Hi Jeremy,
Interesting post, fun read, thanks for making me think! So with VXLAN you get the added benefit of 16 million possible virtual networks (via VNI). This proposal would use traditional VLANs with a 4096 limit? With as many as 1 million VMs in this example that could be tight, no? Perhaps I'm missing something...
Dave
November 20, 2014 at 1:52 p.m. UTC
fabricpath (and probably trill) help with table size through conversational learning - not every switch knows every MAC in a given common VLAN. There's also MAC in MAC encaps so that the spines don't need to learn every MAC address either. I would think the sort of thing you are describing could be pulled off more easily with q-in-q, but at the end of the day, if you have a lot of any to any traffic and don't want to flood, you'll always learn a lot of MACs on your ToRs. So we're back to L3 networks and overlays like VxLAN.
November 28, 2014 at 12:36 a.m. UTC
A similar concept to the first part of your idea actually used to be quite common practice in Token Ring networks with Source Route Bridging and Locally Administered Addresses (LAA's).
December 5, 2014 at 11:28 p.m. UTC
Very interesting concept... It has a lot of merit for single physical site deployments.
if we take the solution forward to the next step: Site diversity for high availability or disaster recovery needs.
How do you think this solution would scale from single site to two or more sites (moving VM's from one site to another while maintaining addressing structure or spanning same IP subnet over multiple sites.) Should we even care since the mac is only locally significant ?
December 12, 2014 at 8:42 p.m. UTC
Interesting read!
I'm a huge fan of fabricpath (I actually had the opportunity to present on it at CiscoLive). From a MAC scaling issue, as Andrew mentioned above, conversationally learning helps drastically decreases the number of MACs learned on each switch. The spine doesn't learn any MACs since it's just forwarding between switch-id's (of course this is complicated when L3 is on the Spine and it now needs to learn adjacency info and MAC info).
Either ways, I like the idea. I think there would be some trivial impact for the hypervisor to inspect/translate ever ARP frame. Additionally, a vmotion is no longer just an MAC move but all devices need to update their ARP entries with the new translated MAC of the host. Which means now we have to ask a new question while troubleshooting connectivity issues -> did all devices (not just gateways but any device in the L2 domain with active ARP entry for the host) update their ARP entries after the vmotion?
Also, maybe this idea isn't too far from implementation. Several vendors (at least Cisco, Juniper, and Arista) utilize broadcom 'merchant silicone' (TridentII) which apparently has a MAC_ADDR_MASK in the my_station_tcam:
some_cisco_switch# bcm-shell module 1 "dump chg my_station_tcam" MY_STATION_TCAM.ipipe0[13]: <VLAN_ID_MASK=0xfff,VLAN_ID=0xdc,VALID=1,MASK=0xfffffffffffffff,MAC_ADDR_MASK=0xffffffffffff,MAC_ADD R=0x5e0001dc,KEY=0xdc00005e0001dc,IPV6_TERMINATION_ALLOWED=1,IPV4_TERMINATION_ALLOWED=1,DATA=0x38,ARP_RARP_TERMINATION_ALLOWED=1 >
December 18, 2014 at 10:02 a.m. UTC
superb article Jeremy - really interesting thanks
December 24, 2014 at 12:56 a.m. UTC
Interesting post Jeremy, although I'm not sure this solution would be any simpler than a L3 fabric & overlay design. One issue also your proposed design does not address is the VLAN scalability limitation. Depending on how many tenants and virtual segments are required, 4096 VLANs may not be enough and you would need to find a away to work around that limitation.
One overlay/tunneling technology that I have seen cloud providers leveraging to provide VM mobility and hide the VM MAC addresses from the core network is Mac-in-Mac. Mac-in-Mac is not new and conceptually is similar to what you are proposing however uses an outer Ethernet header instead of MAC translation to provide MAC and VLAN scalability.
Anas
January 8, 2015 at 7:41 p.m. UTC
Take a look at http://cseweb.ucsd.edu/~vahdat/papers/portland-sigcomm09.pdf
January 10, 2015 at 11:44 a.m. UTC
As a network expert I must say that I’m still struggling to see the real applicability of L2 overlays in many of the use cases where they’re touted to be better than the old. It might just be a technology maturity problem, but in the back of my mind I’m afraid the industry just might have overreacted, responding to a management plane problem.
March 14, 2015 at 11:40 p.m. UTC
Hi Jeremy, good post but what is the advantage of doing that really as insted of doing an ovaelay fabric in DC you do the MAC address translation from whatever to your internal MAC hierarchy schema (BGP or IS-IS in current overlays). L3 overlays where chosen for a couple of reasons like for example faster convergence than L2 technologies and more a couple more I think, so if you think your L2 fabric is better than currently proposed L3 fabrics please write propose an RFC as this might be interesting :)
March 19, 2015 at 10:33 a.m. UTC
Interesting thought, but I still would lean towards VxLAN and the (upcoming) EVPN extensions (all overlaying an L3-constructed L2 path of course (TRILL, FP, OTV, etc.)) - use BGP to learn every MAC address within the DC, and get 16M VLANs.
What would be even more interesting/convoluted: hybrid the two. Have all of the MACs behind the VTEP aggregate, and what BGP would exchange would be those aggregates vs. every end-node MAC. (Disclaimer: just thinking out loud here.) ... when an instance moves, it would get a new MAC from your MAT Engine/Controller and carry on ... would work, right?
I wonder if doing both falls into the category of more trouble than it's worth?
/TJ PS - love the anti-spam challenge below, much better than the usual captcha.
March 20, 2015 at 7:04 a.m. UTC
I am not too much excited about the application of L2 overlay. It sometimes seems to be better stick to the old guard than practice this thing for fewer advantages. Rest all aside, good read!
August 5, 2015 at 10:11 a.m. UTC
Interesting post, but what about the VM's ARP cache!! For example, VM1,VM2,and VM3 would cache the Pseudo MAC address (e.g., xx:xx:xx:01:46:4B) of VM4. Now, if the VM4 has been moved to other edge switch, then it will get another Pseudo MAC address based on its new location, but VM1,VM2,and VM3 still cache the old Pseudo MAC address (the wrong HW address) of VM4. Moreover, what will happen if a new VM5 has taken the previous location (i.e., port in edge switch) of VM4 after VM4 was moved to another edge switch in DC?
November 26, 2015 at 11:52 a.m. UTC
This strikes me as something SDN could help with as technologies like openflow allow you to directly mess with the flow databases in switches.
A rather simple (and not likely that scalable) method being that when a MAC address is learned it's bounced to the SDN controller and the SDN controller evaluates whether it warrants changing the flow info on the switch. In fact you could almost turn off MAC learning on the aggregate layer and the controller learns MACs from the Edge switches and performs any necessary aggregation before pushing them to the aggregate switches. The net effect being the aggregate switches handling inter-rack communication theoretically only get the aggregated routes.
I guess we'd still need switching ASICs to catch up as I doubt there are many (if any) that have support for 'best match' processing in hardware.