The premiere source of truth powering network automation. Open and extensible, trusted by thousands.
NetBox is now available as a managed cloud solution! Stop worrying about your tooling and get back to building networks.
TCP Windows and Window Scaling
By stretch | Wednesday, August 4, 2010 at 1:04 a.m. UTC
I remember a conversation I once had with a coworker while I was working as a network administrator in Iraq. He wanted to know whether upgrading our meager (and extremely expensive) 2 Mbps satellite Internet connection would be sufficient to play XBox Live. I replied that it wouldn't matter if we had a 1 Gbps connection. Why? Because it was still hindered by one-way latency of around 250 msec, not counting the delay from the upstream satellite hub in the UK to servers in the US. With that kind of round-trip delay, you'd get your head blown off in Call of Duty before you even realize the game has started.
"Long, fat networks" such as ours, so called because of their relatively high delay and high bandwidth, posed an interesting problem for early TCP implementations. To understand this issue, first we must familiarize ourselves with TCP windowing.
TCP Windowing
As we know, TCP is a connection-oriented protocol; both ends of a connection keep strict track of all data transmitted, so that any lost or jumbled segments can be retransmitted or reordered as necessary to maintain reliable transport. To compensate for limited buffer space (where received data is temporarily stored until the appropriate application can process it), TCP hosts agree to limit the amount of unacknowledged data that can be in transit at any given time. This is referred to as the window size, and is communicated via a 16-bit field in the TCP header.
Suppose we have two hosts, A and B, that form a TCP connection. At the start of the connection, both hosts allocate 32 KB of buffer space for incoming data, so the initial window size for each is 32,768.

Host A needs to send data to host B. It can tell from host B's advertised window size that it can transmit up to 32,768 bytes of data (in intervals of the maximum segment size, or MSS) before it must pause and wait for an acknowledgment. Assuming an MSS of 1460 bytes, host A can transmit 22 segments before exhausting host B's receive window.
When acknowledging receipt of the data sent by host A, host B can adjust its window size. For example, if the upper-layer application has only processed half of the buffer, host B would lower its window size to 16 KB. If the buffer was still entirely full, host B would set its window size to zero, indicating that it cannot yet accept more data.
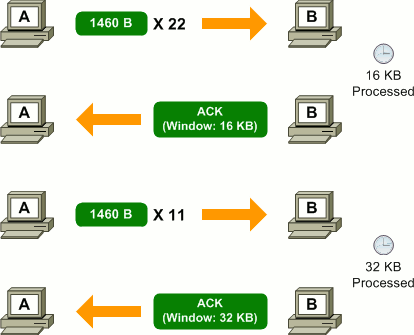
On a LAN with high bandwidth and extremely low delay, windows are rarely stressed as there are typically very few segments in transit between two endpoints at any given time. On a high-bandwidth, high-delay network, however, an interesting phenomenon occurs: it is possible to max out the receive window of the destination host before receiving an acknowledgment.
As an example, let's assume a TCP connection is established between two hosts connected by a dedicated 10 Mbps path with a one-way delay of 80ms. Both hosts advertise the maximum window size of 65,535 bytes (the maximum value of a 16-bit unsigned integer). We can calculate the potential amount of data in transit in one direction at one point in time as bandwidth * delay: 10,000,000 bps divided by 8 bits per byte, multiplied by 0.08 seconds equals 100,000 bytes. In other words, if host A begins transmitting to host B continuously, it will have sent 100,000 bytes before host B receives the first byte transmitted. However, because our maximum receive window is only 65,535 bytes, host A must stop transmitting once this number has been reached and wait for an acknowledgment from host B. (For the sake of simplicity, our example calculations do not factor in overhead from TCP and lower-layer headers.) This delay wastes potential throughput, unnecessarily inflating the time it takes to reliably transfer data across the network. TCP window scaling was created to address this problem.
Window Scaling
Window scaling was introduced in RFC 1072 and refined in RFC 1323. Essentially, window scaling simply extends the 16-bit window field to 32 bits in length. Of course, the engineers could not simply insert an extra 16 bits into the TCP header, which would have rendered it completely incompatible with existing implementations. The solution was to define a TCP option to specify a count by which the TCP header field should be bitwise shifted to produce a larger value.
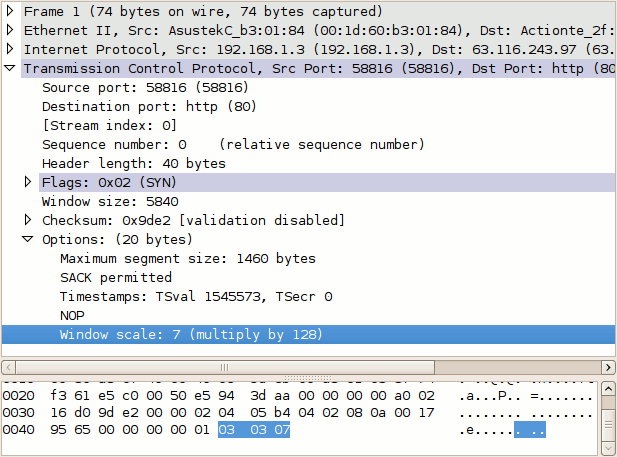
A count of one shifts the binary value of the field to left by one bit, doubling it. A count of two shifts the value two places to the left, quadrupling it. A count of seven (as shown in the example above) multiplies the value by 128. In this manner, we can multiply the 16-bit header field along an exponential scale to achieve more than sufficiently high values. Of course, this causes us to lose granularity as we scale (we can only increase or decrease the window size in intervals of 2n where _n_ is our scale), but that isn't much of a concern when dealing with such large windows.
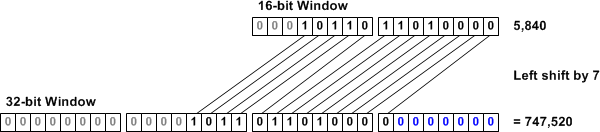
The window scaling option may be sent only once during a connection by each host, in its SYN packet. The window size can be dynamically adjusted by modifying the value of the window field in the TCP header, but the scale multiplier remains static for the duration of the TCP connection. Scaling is only in effect if both ends include the option; if only one end of the connection supports window scaling, it will not be enabled in either direction. The maximum valid scale value is 14 (section 2.3 of RFC 1323 provides some background on this caveat for those interested).
Revisiting our earlier example, we can observe how window scaling allows us to make much more efficient use of long fat networks. To calculate our ideal window, we double the end-to-end delay to find the round trip time, and multiple it by the available bandwidth: 2 * 0.08 seconds * 10,000,000 bps / 8 = 200,000 bytes. To support a window of this size, host B could set its window size to 3,125 with a scale value of 6 (3,125 left shifted by 6 equals 200,000). Fortunately, these calculations are all handled automatically by modern TCP/IP stack implementations.
Posted in Packet Analysis
Comments
August 4, 2010 at 3:48 a.m. UTC
Excellent post stretch!
August 4, 2010 at 4:23 a.m. UTC
Great post on TCP Window Scaling! I'd personally pick nits with the last sentence, as I mostly hate the Windows 7 TCP stack and its lack of ability to be manually tuned effectively... :)
All together great explanation, though, and a good writing style. I also like the exhibits you've got.
Thanks!
@SomeClown
packetqueue.net
August 4, 2010 at 6:24 a.m. UTC
Good post, as ever :)
I'll start with a nitpick... The Bandwidth Delay Product (BDP) is usually calculated using the round trip time (RTT) rather than one way delay.
The reason for this is that while the amount of data on the wire is determined by the one way delay, the first ACK doesn't arrive back at the source until an RTT has passed. This means that for a session to completely fill a link it needs to have a window that equals the bandwidth of the link multiplied by the RTT.
The last sentence brings up an alternative strategy here: the BDP determines the maximum throughput of a single TCP session. In order to increase this throughput you could increase the window, or you could open more sessions. If you take a look at the number of sessions opened when you go to Google Maps you may be surprised by the result. By using a large number of parallel connections they can increase the speed without having to assume well tuned TCP stacks.
One thing to be aware of when using large windows is packet loss. When you use large windows you are essentially saying that you trust the network to accept a large amount of data and carry it to the destination. Errors happen. If you are the only session on a dedicated pipe then you will only be at risk of bit errors, which should be low on most circuits; however if you are sharing a pipe then you may well experience congestion. By increasing your window you are also increasing the amount of data that could be affected in the time it takes you to react to congestion conditions.
Another TCP Option that helps in this situation is Selective Acknowledgments (SACK). I notice in the trace above the options section lists "SACK permitted". Traditional TCP ACK is a simple incremental counter. It acknowledges how much contiguous good data has been received. If you drop one segment in the middle of a transmission window then any good data received after the dropped segment needs to sit there unacknowledged and may trigger additional retransmissions at the source. SACK allows the destination host to acknowledge traffic that has been received after a missing segment reducing the number of retransmissions required.
A topic for another post perhaps?
August 4, 2010 at 7:30 a.m. UTC
"Fortunately, these calculations are all handled automatically by modern TCP/IP stack implementations."
"Fortunately" i don´t use windows vista nor 7 usually, but it´s autotuning behavior is stupid as hell. First thing that i do when i "need" to use a vista/7 is disable its way to negotiate the window scaling options:
netsh int tcp set heuristics disabled
or more flexible way to tune with:
netsh int tcp set global autotuninglevel= ()
where () could be: normal/disabled/restricted/experimental
btw great post Stretch!
August 4, 2010 at 8:08 a.m. UTC
Great post as always :)
But: your bandwidth*delay calculations are all wrong:
If you multiply 1,536,000 bits/second by 0.08 seconds you get 122,800 bits or 15,360 bytes which doesn't exhaust the receivers buffer at all ;)
Best,
Falk
August 4, 2010 at 12:27 p.m. UTC
Great post! What a great foray into (possibly) my favorite RFC - 3135 Performance Enhancing Proxies Intended to Mitigate Link-Related Degradations. While a better TCP stack, really TCP congestion avoidance algorithms more suited for high latency links (TCP Hybla) would do the job. Sometimes a PEP device is a more scalable way to go for users behind a portion of a network. Riverbed, Cisco WAAS etc have this capability, along with others techniques to make the most out of link related degradation. TCP "ramp-up latency" as a result of TCP slow-start, or the ability to open the TCP window sufficiently fast enough is one significant contributor to the reduced throughput. Huge gains can be made on a VSAT network where RTT typically exceeds ~500 ms when using a PEP.
August 4, 2010 at 1:02 p.m. UTC
@chewtoy Actually, SACK already was explained on a blog post.
@stretch Great post, as usual =) Interesting that not long ago I was suffering from a problem with a storm of TCP Window Zero between two proxys, application problem but curious nevertheless.
August 4, 2010 at 2:21 p.m. UTC
@Falk: Doh! Good catch. I knew something about that math seemed off, but after four hours researching and writing I suppose my diligence was less than what was due. I've fixed the numbers in the examples. Thanks for the catch!
August 4, 2010 at 4:57 p.m. UTC
Nice writeup....finally got a good understanding of how tcp window scaling works.
Cheers!!
August 4, 2010 at 7:37 p.m. UTC
Yes,
WAN Acceleration hardware (and software) from vendors like Riverbed and Cisco have methods to optimize "Elephants" (LFN's or Long Fat Networks).
In Riverbed's case they combine TCP acceleration techniques, such as "Virtual Window Expansion (VWE)" or normal WAN links, but for LFN's (long-haul, high-latency links such as satellite) you can enable HS-TCP (High-Speed TCP - see RFC 3649). When using HS-TCP you need to calculate Bandwidth Delay Product to set the buffers.
VWE is a product of the use of "Scalable Data Reduction", or sending less over the WAN. SDR is not just compression, but clever use of storing data in bit-streams on WAN Accelerator disk and sending only "references" to that data when the same bitstream is requested over the WAN. SO it doesn't matter if the data is sent using FTP, CIFS or HTTP. Clever stuff.
In addition to optimising TCP, Other protocol-specific acceleration techniques can be used as well. "Read Ahead and Write Behind, MAPI pre-population.
The list goes on!
August 4, 2010 at 7:44 p.m. UTC
I think that Stretch is RIGHT when he calculates optimum window size:
-
Bandwidth Delay Product = (bandwidth * RTT) / 8
-
Optimum Window Size = 2 * BDP
-
Buffer size = BDP / MTU
August 4, 2010 at 8:40 p.m. UTC
@drak - D'oh. Must have missed that one /me slaps forehead
August 6, 2010 at 12:09 a.m. UTC
High latency links also suffer from the effects of TCP Congestion Control and 'slow start'. There's an interesting 'stepping' that occurs when you plot retrieval times for increasing sized files.
http://mike.bailey.net.au/blog/?p=38
I've written a web based tool to plot these effects available at:
http://brightbox.latentsee.com/
- Mike
August 6, 2010 at 2:41 a.m. UTC
Great Post!
August 18, 2010 at 6:22 p.m. UTC
August 21, 2010 at 9:18 p.m. UTC
This was a great refresher of some critical TCP/IP concepts. One tends to take the specifics for granted after a while. Also, it's the best explanation I've found yet on TCP Window Scaling. Easy to understand examples and graphics were a big help. Thanks and well done!
July 10, 2011 at 3:28 a.m. UTC
It's a good article, but I misunderstand one thing. Why is windows size 3150 and scale 6? Can they be 6300 and 5, or 1260 and 4, or 50000 and 2?
November 17, 2011 at 8:10 p.m. UTC
Any idea why Google use a window size of 5720 on their Linux machines rather than the Linux default of 5840?
More info here:
http://www.netresec.com/?page=Blog&month=2011-11&post=Passive-OS-Fingerprinting
January 13, 2012 at 3:40 p.m. UTC
That was the best explanation of the issue that I have ever seen…anywhere. Thank you!
June 10, 2012 at 7:52 p.m. UTC
didn't understand anything about this in computer networking class, so thank you so much for teaching me! :) great post
August 3, 2012 at 6:00 p.m. UTC
very good thanks
October 7, 2012 at 2:10 a.m. UTC
Jeremy, you have done an excellent job of explaining the elusive TCP Window and Window Scaling concepts in crystal clear form in just one page with appropriate diagrams. Thanks a lot!
October 25, 2012 at 2:35 a.m. UTC
Awesome! Thanks for the info!
November 5, 2012 at 10:38 p.m. UTC
Great post, learned a lot :)
November 10, 2012 at 5:49 p.m. UTC
The Windows 7/Vista implementation of the protocol, including all tunable parameters and discussion of the auto-tuning on a single page can be found here:
http://www.speedguide.net/articles/windows-7-vista-2008-tweaks-2574
December 27, 2012 at 6:00 p.m. UTC
Good one. Many thanks!
January 2, 2013 at 1:31 p.m. UTC
Thank you very much for the explanation.
June 13, 2013 at 9:32 p.m. UTC
@darenmatthews ... use of RTT is incorrect in your example. One way delay should be used if you are going to multiply by 2!
If you use RTT, no need to multiply by BDP by 2 - savvy? :)
June 17, 2013 at 10:42 a.m. UTC
Got an exam tomorrow and this help a lot Thanks!
July 1, 2013 at 6:35 p.m. UTC
One thing i dont understand, if the scaling can only be set during the tcp setup, how does the OS decide on the value before transmitting traffic ?
October 30, 2013 at 7:38 a.m. UTC
Clearest explanation I've read. Congratulations, sir.
March 2, 2014 at 11:20 a.m. UTC
Excellent explanation. Thank you!
April 3, 2014 at 8:30 a.m. UTC
thank you so much!!! accurate and clearly explanantion
June 12, 2014 at 3:57 a.m. UTC
Thanks, nice post.
July 7, 2014 at 4:29 a.m. UTC
This is by-far the best explanation I have come across for TCP Window scaling! Thank you soo much!!
August 23, 2014 at 5:51 a.m. UTC
What happens if working with variable latency and oversubscription. I am aware that at this point you have more problems than just tuning the TCP. I am just curious if it would make sense to lower down maximum window size and decrease sending buffers on end stations to decrease load on affected segments? How should you tune intermediate buffers on networking equipment to avoid buffer-bloat while giving packets enough chance to float through within the interval?
Thank you and I apologize if my question is out of place.
September 12, 2014 at 10:24 a.m. UTC
Good one!!well explained
February 18, 2015 at 4:57 p.m. UTC
Hi Jeremy,
Excellent article. appreciated.
time to time, i will come up with bunch of questions :)
Thanks, Prabha
April 26, 2015 at 5:12 p.m. UTC
Excellent Article.. Very simple and clear explanation..
Thanks Jeremy..
Regards Nitin
June 10, 2015 at 7:58 p.m. UTC
I must agree with other comments, this is a well written article. Love the real world reference. You are pretty good at explaining these kinds of things! Thanks!
July 16, 2015 at 10:53 a.m. UTC
Very well written article. Thank you very much for a perfect explanation!
December 20, 2015 at 7:57 a.m. UTC
Amazing Post :-). Will recommend it.
March 31, 2016 at 1:55 a.m. UTC
@chewtoy cool replenish. your post helps clarified BDP and SACK
June 22, 2016 at 9:03 p.m. UTC
Great article. Good, clear explanation.
Thanks
August 27, 2016 at 5:04 p.m. UTC
question: - in the example above, if the other end does not support window scale, the resulting window size would be 5840 ? as someone pointed out, why not set the window size to 46720 and the window scale to 4 which would yield the same 747 520 and a better granularity ? Wouldn't be best to use a window size always between 32768 and 65535 and just play with the window scale ?
September 26, 2016 at 4:18 a.m. UTC
Great article thanks. It's interesting how different ISP providers and major web sites set the values for the initial window size and value of windows scaling. Easy to see when I view the syn-ack packet back within tcpdump output. Seems the f5 load balancers set a fairly small window size of 4K but when you connect to google.com its set as high as 49k and aws doesn't use tcp time stamps but 8k window size. I'm collecting various response times, window sizes and the windows scaling values to determine what to use myself. You can see your own values and other internet sites here: http://tcpcheck.com/
October 5, 2016 at 11:50 a.m. UTC
Cool stuff! Still usefull 6 years later. Thank you Jeremy!