The premiere source of truth powering network automation. Open and extensible, trusted by thousands.
NetBox is now available as a managed cloud solution! Stop worrying about your tooling and get back to building networks.
Can You Keep a Secret?
By stretch | Sunday, February 7, 2016 at 7:44 p.m. UTC
I've been developing an IPAM/DCIM tool for work over the past several months (more on that soon), and recently my focus has been on expanding it to store confidential data associated with network devices. Backup login credentials, TACACS+/RADIUS secrets, SNMP communities, and so on: Short strings that need to be stored securely.
Hashing
Storing a password or other small piece of sensitive data is different from merely authenticating against it. Most password storage mechanisms never actually store a user's actual password, but rather an irreversible hash of it. (That is if you're doing it correctly, at least.)
For example, the Django Python framework (which powers packetlife.net) by default employs salted SHA256 hashes to authenticate user passwords. When a password is saved, a random salt is generated and concatenated with the plaintext password. (A salt is used to prevent two identical passwords from producing the same hash.) The SHA256 algorithm is then run against the whole thing to produce a fixed-length hash. Here's an example in Python using Django's built-in make_password() function:
>>> from django.contrib.auth.hashers import make_password
>>> make_password("MyP@ssw0rd!")
u'pbkdf2_sha256$12000$x5E0yB2dh13m$ablUOER8qn4CxjmHZlJrUUA1Cb9MeLXvfggTnG56QpM='
The resultant hash consists of several components, separated by the $ character:
- pbkdf2_sha256 - The type of hash (PBKDF2)
- 12000 - The number of iterations performed
- x5E0yB2dh13m - The random salt used
- ablUOER8qn4CxjmHZlJrUUA1Cb9MeLXvfggTnG56QpM= - The Base64-encoded hash
The iterations count indicates that the hashing function was run not just once, but 12 thousand times in succession. Why so many iterations? It places an artificial computational burden on an attacker: The attacker must perform 12,000 hashes per password attempted, which helps mitigate brute-force attacks.
This is all great for validating passwords, but it doesn't allow us to retrieve passwords from the database. For that, we need encryption.
Encryption
We can use Advanced Encryption Standard (AES), a form of symmetric encryption, to securely store our secret data. AES allows for keys of 128, 192, or 256 bits in length. We'll opt for the 256-bit flavor since we're not platform-constrained. This means we need a 256-bit (or 32-byte) key, which we'll generate randomly:
>>> import os >>> encryption_key = os.urandom(32) >>> encryption_key '\xc4\xfb\x90\x1b\x04\x0b\xe5\x1f\xdb\x854t\x14S\xda=\x8c\xb2U\xe14\xd8\x90B\x0buU\xb7s\xeb\x9b\x03'
Using the AES library provided by pycrypto, we can encrypt data with this key. But first, we have to pad our plaintext data to the AES block size of 128 bits (16 bytes). For example, suppose we want to encrypt the string "Your secret goes here". That's 21 bytes long, so we'll need add padding to increase its length to the nearest multiple of 16, which is 32 bytes, using null bytes. (There are several better ways to implement padding, but this approach suffices for the purposes of this article.)
>>> plaintext = "Your secret goes here" >>> len(plaintext) 21 >>> padding = (32 - len(plaintext)) * chr(0) >>> plaintext += padding >>> plaintext 'Your secret goes here\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' >>> len(plaintext) 32
Now we can encrypt our data using the key we generated earlier:
>>> cipher = AES.new(encryption_key) >>> ciphertext = cipher.encrypt(plaintext) >>> ciphertext 'R]\x84*\xe9\x87\xbeL3\xbao\x84\xd4\xab\x1d3\xb8\xdc\x7f\x1c>\xc7J\xd3\xb7SB\xaf\xa6\xba\xda\x9d' >>> len(ciphertext) 32
You'll note that the length of our ciphertext is the same as our padded plaintext: AES doesn't add any storage overhead (aside from the plaintext padding).
This ciphertext can be safely stored in a database, because it's useless without the encryption key. This key is used to decrypt the ciphertext:
>>> cipher = AES.new(encryption_key)
>>> plaintext = cipher.decrypt(ciphertext)
>>> plaintext
'Your secret goes here\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
>>> plaintext.replace('\x00', '')
'Your secret goes here'
Encryption which uses one key for both encryption and decryption is called symmetric. This is in contrast to asymmetric encryptions like RSA, which use separate public and private keys for encryption and decryption operations, respectively.
Great, so now we can encrypt all the things, right? Well, we're not quite done yet. Let's try encrypting another plaintext with the same key...
>>> plaintext2 = "Your secret goes over here too" >>> padding = (32 - len(plaintext2)) * chr(0) >>> cipher = AES.new(encryption_key) >>> ciphertext2 = cipher.encrypt(plaintext2 + padding) >>> ciphertext2 'R]\x84*\xe9\x87\xbeL3\xbao\x84\xd4\xab\x1d3(g\xe1\xd3F\xfa\xec\x11\xd9=\xbc\xb0\x9cSO\xed'
Take a close look at that ciphertext, and you'll notice that the first 16 bytes are the same as the ciphertext of the first string!
>>> ciphertext[0:16] 'R]\x84*\xe9\x87\xbeL3\xbao\x84\xd4\xab\x1d3' >>> ciphertext2[0:16] 'R]\x84*\xe9\x87\xbeL3\xbao\x84\xd4\xab\x1d3'
This is because the first 16 bytes of our two plaintexts are identical. By default, pycrypto's AES implementation will use electronic codebook (ECB) mode of of operation. ECB encrypts every block (16-byte segment) independently, so if two identical plaintext blocks are encrypted using the same key, the two resulting ciphertext blocks will also be identical. This means an attacker can tell when information is repeated.
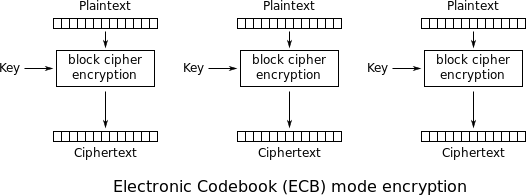
Fortunately, we have other, more robust cipher modes to choose from. Cipher feedback (CFB), for example, uses a random initialization vector (IV) equal to the block length to introduce some randomness to the encryption process. (It's similar in concept to the salt we used to generate a unique SHA256 hash.) The IV is used to seed the first block cipher, and each successive block uses the output ciphertext of its predecessor as its own IV.
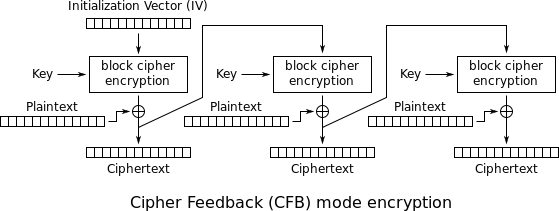
Let's try encrypting both plaintexts again, this time using CFB mode with a random IV for each.
>>> iv1 = os.urandom(16) >>> iv2 = os.urandom(16) >>> plaintext1 = "Your secret goes here" >>> plaintext1 += (32 - len(plaintext1)) * chr(0) >>> plaintext2 = "Your secret goes over here too" >>> plaintext2 += (32 - len(plaintext2)) * chr(0) >>> cipher = AES.new(encryption_key, AES.MODE_CFB, iv1) >>> ciphertext1 = cipher.encrypt(plaintext1) >>> cipher = AES.new(encryption_key, AES.MODE_CFB, iv2) >>> ciphertext2 = cipher.encrypt(plaintext2) >>> ciphertext1[0:16] 'S\xc7\xde\x13Ef\xde\xa8\xe2\xe0E\x03\x0c\x85"V' >>> ciphertext2[0:16] '\x05\xd4\x0eO\x0b?\xe7\xce\xfdi\xe2s5\x8fA\x82'
This time our two ciphertexts are completely different. Note that while an IV itself is not considered sensitive, it must be stored along side its ciphertext. Both it and the encryption key are necessary to decrypt the data.
>>> cipher = AES.new(encryption_key, AES.MODE_CFB, iv1)
>>> cipher.decrypt(ciphertext1).replace('\x00', '')
'Your secret goes here'
>>> cipher = AES.new(encryption_key, AES.MODE_CFB, iv2)
>>> cipher.decrypt(ciphertext2).replace('\x00', '')
'Your secret goes over here too'
One more important observation is that AES will happily decrypt ciphertext using any properly formatted key. It has no built-in way to validate whether the resulting plaintext is correct.
>>> wrong_key = os.urandom(32)
>>> cipher = AES.new(wrong_key, AES.MODE_CFB, iv1)
>>> cipher.decrypt(ciphertext1).replace('\x00', '')
'\xa2\x93\x885(\x84\xb7\xcc\xba\xf5D{\x0e\xf2\x18\xd9\xfb\xe87E\xf7\x88P^\xb8\xfe\xf1\x01\x0c\xcd\xddQ'
In practice, we'd store both the ciphertext and a hash of the plaintext. The hash can be used to validate that the ciphertext was decrypted using the correct key.
Excellent! Now we've got a secure way to store secret data in a database. But all we've really accomplished is moving the problem around. Now instead of worrying about how to store our sensitive data, we have to worry about where to store the encryption key. Anyone with a copy of the key can decrypt our data. This means that any time the key is compromised, the entire data store has to be re-encrypted using a new key.
In part two, we'll see how asymmetric cryptography can be used to share the encryption key among multiple parties.
Posted in Security
Comments
February 10, 2016 at 6:43 p.m. UTC
You had previously mentioned the IPAM/DCIM you were working on would not be something you'd be able to release. The IPAM/DCIM you've mentioned, is the situation still the same? I love the idea of an IPAM/DCIM built by a network engineer for network engineers.
February 13, 2016 at 10:32 p.m. UTC
Jordan,
Look into phpIPAM. Built by a network geek, for network geeks. I have been using it for long enough now that I can imagine going back to racktables or some other solution. I am curious about Jeremy's solution, but it would have to have multiple killer features for me to leave behind Miha's work.
February 14, 2016 at 3:35 a.m. UTC
I've played around with the phpIPAM demo, and I think it's a decent product for small networks, but it doesn't come anywhere near what's needed at moderate scale. It also has no DCIM, circuit tracking, or credentials storage component.
May 15, 2017 at 3:45 a.m. UTC
English is not my native language. But this article really help me ALOT to understand how encryption can be done within python.
Thank you very much. Kudos!