The premiere source of truth powering network automation. Open and extensible, trusted by thousands.
NetBox is now available as a managed cloud solution! Stop worrying about your tooling and get back to building networks.
IBGP as an IGP
By stretch | Monday, March 14, 2011 at 12:33 a.m. UTC
A BGP adjacency can be described as either internal (between two routers in the same autonomous system) or external (between two routers in different autonomous systems). The same protocol is run in either case, with just a few tweaks to the way route advertisement is handled. The term "internal" leads many newbie networkers to consider the potential deployment of IBGP as an interior routing protocol. Although this is typically and appropriately dismissed as a bad idea, few people take the time to examine the reasoning behind the conclusion.
This article discusses five major weaknesses of IBGP as interior routing protocol. It is important to understand that this article does not assert that IBGP cannot function as an interior routing protocol. Rather, it explains why IBGP is a poor choice for the role given the availability of alternative protocols.
No Dynamic Neighbor Discovery
One of the major features of all modern interior routing protocols is the ability to automatically discover and form adjacencies with neighboring routers on links with broadcast capability. BGP, by contrast, requires the explicit configuration of all neighbors. While it may be desirable to always statically configure neighbors in any routing protocol for security reasons, dynamic neighbor discovery is a valuable feature for less hands-on network deployments.
Complex Path Selection Process
IGPs determine the best path for a destination based on relatively simple metrics. EIGRP uses a combination of overall delay and minimum available bandwidth, whereas OSPF and IS-IS use link cost. All of these are easily tuned to meet the needs of the network operators. In all cases, the route with the lowest metric wins.
BGP, on the other hand, employs a rather complex path selection process to determine the best route for a destination. By default, no meaningful metric is carried by IBGP advertisements within an autonomous system (AS).
The Full Mesh Requirement and Route Recursion
By default, a BGP router will not advertise a network learned from one IBGP peer to another. If IBGP is used as an IGP, this presents severe scaling problems; every router would have to peer with every other router on the network.
The full-mesh requirement can be overcome by carefully designating intermediate routers as route reflectors, but we're still left with the issue of excessive route recursion. Consider the topology below, where R2 and R3 are reflecting IBGP routes between their neighbors.
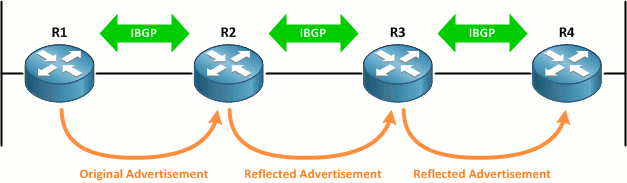
Although end-to-end connectivity is achieved, the routing tables on R1 and R4 are needlessly complex. R1's table looks like this:
R1# show ipv6 route
IPv6 Routing Table - 10 entries
Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP
U - Per-user Static route, M - MIPv6
I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary
O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2
ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
D - EIGRP, EX - EIGRP external
C 2001:DB8:0:1::/64 [0/0]
via ::, Loopback0
L 2001:DB8:0:1::1/128 [0/0]
via ::, Loopback0
B 2001:DB8:0:2::/64 [200/0]
via 2001:DB8:0:12::2
B 2001:DB8:0:3::/64 [200/0]
via 2001:DB8:0:23::3
B 2001:DB8:0:4::/64 [200/0]
via 2001:DB8:0:34::4
C 2001:DB8:0:12::/64 [0/0]
via ::, FastEthernet0/0
L 2001:DB8:0:12::1/128 [0/0]
via ::, FastEthernet0/0
B 2001:DB8:0:23::/64 [200/0]
via 2001:DB8:0:12::2
B 2001:DB8:0:34::/64 [200/0]
via 2001:DB8:0:23::3
L FF00::/8 [0/0]
via ::, Null0
In order for CEF to resolve the next hop address of, for example, 2001:db8:0:4::1, it must perform a recursive lookup for every hop in the BGP path. In this case, this requires three lookups:
- 2001:DB8:0:4::/64 via 2001:DB8:0:34::4
- 2001:DB8:0:34::/64 via 2001:DB8:0:23::3
- 2001:DB8:0:23::/64 via 2001:DB8:0:12::2 (which is directly connected)
This recursive resolution is performed only in response to routing updates, not per packet, but it does introduce significant convergence delays. The following output from debug ip cef table shows that routes with next hops which cannot be immediately resolved are queued for later processing. (The example below is from a similar IPv4 topology, as the IPv6 version of the command produced no output.)
CEF-Table(Default-table): Event up 10.0.4.0/24 (rdbs:1, flags:1A00000) CEF-Table: attempting to resolve 10.0.4.0/24 CEF-IP: can't resolve 10.0.4.0/24 via 10.0.34.4 CEF-IP: Failed to instantly resolve recursive entry 10.0.4.0/24, queued for background resolution
Compare the routing table above to the one produced by OSPFv3 running on the same topology. Every route is advertised with a directly connected next hop address, removing the burden of route recursion.
R1# show ipv6 route
IPv6 Routing Table - 10 entries
Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP
U - Per-user Static route, M - MIPv6
I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary
O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2
ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2
D - EIGRP, EX - EIGRP external
C 2001:DB8:0:1::/64 [0/0]
via ::, Loopback0
L 2001:DB8:0:1::1/128 [0/0]
via ::, Loopback0
O 2001:DB8:0:2::/64 [110/11]
via FE80::C002:18FF:FEE5:0, FastEthernet0/0
O 2001:DB8:0:3::/64 [110/21]
via FE80::C002:18FF:FEE5:0, FastEthernet0/0
O 2001:DB8:0:4::/64 [110/31]
via FE80::C002:18FF:FEE5:0, FastEthernet0/0
C 2001:DB8:0:12::/64 [0/0]
via ::, FastEthernet0/0
L 2001:DB8:0:12::1/128 [0/0]
via ::, FastEthernet0/0
O 2001:DB8:0:23::/64 [110/20]
via FE80::C002:18FF:FEE5:0, FastEthernet0/0
O 2001:DB8:0:34::/64 [110/30]
via FE80::C002:18FF:FEE5:0, FastEthernet0/0
L FF00::/8 [0/0]
via ::, Null0
Convergence Delays
Configured with its default 10-second hello timer and 40-second dead timer, OSPF will take between 30 and 40 seconds to react to an indirect adjacency failure (that is, a failure which does not transition the interface status). BGP's default hello and hold timers are 60 and 180 seconds, respectively; BGP can take up to three minutes to respond to an indirect failure. The two log messages below were generated by the OSPF and BGP processes in response to the same failure; the BGP notification occures more than two minutes after the OSPF notification.
00:19:37: %OSPFv3-5-ADJCHG: Process 1, Nbr 2.2.2.2 on FastEthernet0/0 from FULL to DOWN, Neighbor Down: Dead timer expired 00:21:42: %BGP-5-ADJCHANGE: neighbor 2001:DB8::2 Down BGP Notification sent
Although the timers of both protocols may be tuned to much lower values, these default values provide an idea of how quickly either protocol is intended to react. Configuring BGP's hold time to less than 20 seconds on IOS invokes the following warning:
Router(config-router)# timers bgp 5 15 % Warning: A hold time of less than 20 seconds increases the chances of peer flapping
It is also worth noting that in Cisco IOS, BGP adjacencies are not tied to the state of an interface as is an IGP like OSPF; whereas an OSPF adjacency over an interface is deleted immediately upon shutting the interface down, a BGP adjacency will be maintained until it times out. BGP was intended to function so long as any path to an adjacent router is available; it is not bound to any particular interface.
Licensing
Finally, the right-to-use licensing for router software which supports BGP often costs more than a basic license with only IGP support. This is an especially important decision when implementing a routed access edge.
Posted in Routing
Comments
March 14, 2011 at 1:07 a.m. UTC
Stretch, when is it appropriate to use iBGP?
March 14, 2011 at 1:07 a.m. UTC
BGP convergence can be improved with BFD. Turn up BFD on the interfaces, set 'fall-over bfd' on the neighbors. For platforms that don't support BFD, fast peering detection via 'fall-over' is also an option. The esteemed Ivan Pepelnjak has written just such an article: http://www.nil.com/ipcorner/DesigningBGPNetworks/
You can mitigate the configuration scalability issue on your route reflectors with BGP dynamic neighbor discovery, 'bgp listen' on IOS or 'allow' in Junos. Note, the IOS command seems to only be available on higher end platforms - e.g. the ASR.
March 14, 2011 at 10:36 a.m. UTC
Some remarks:
1) "No dynamic discovery" is not really a disadvantage. Actually, for OSPF network I prefer 'passive-interface default' in most cases.
2) Not so complex. Look at EIGRP. =)
3) May be. But not really the main problem. We can always play with route-reflectors, confederations and next-hop-self.
Number 4 (convergence) is really one of the main reasons. That's clear. BFD isn't enough. We have to consider bgp scanner, update batching, etc.
Here is a great post about BGP convergence:
http://blog.ine.com/2010/11/22/understanding-bgp-convergence/
Another significant reason not to use BGP as IGP is that it's "a bad idea". =)
It's simply impossible to configure that correctly in redundant topology. If loopback is the source for BGP updates, static or IGP is mandatory. If not, network will never work correctly.
Just to clarify. The post is very nice anyway. And it will be very useful for beginners.
March 14, 2011 at 2:28 p.m. UTC
BGP is designed as an exterior gateway protocol. iBGP facilitate the reachability to other iBGP peers such as BGP route reflectors. It should not be used as an IGP. There is generally no good reason to use BGP as an IGP.
It is true that BFD can increase the protocol awareness of the interface failure. However consider the case when your upstream eBGP interface is down due to a physical problem and then quickly recovered, you may not want to BGP to react to such temporal event. You would not want to update 300k prefixes for your BGP topology for such case.
March 14, 2011 at 2:29 p.m. UTC
@sam: IBGP is used whenever you need to run BGP internally; e.g. to share a full routing table between two edge routers.
@StuckInActive: I didn't bother covering BFD since it's really an independent protocol which can be employed by IGPs as well.
@Petr: 1) Like I said in the article, although you may not have a use for neighbor discovery, many organizations prefer it.
2) EIGRP employs a simple numeric metric. Yes, the calculation to arrive at the metric is a tad complex, but in the end it's just a number like OSPF's cost. By contrast, IBGP evaluates various route attributes including weight (on IOS), local preference, and origin. Further, IBGP assigns no useful metric by default.
3) As the article explains, using route reflectors does not solve the problem of excessive route recursion.
March 15, 2011 at 6:59 a.m. UTC
@misteryiz: Scale. Modern SP design suggests IGP such as OSPF or ISIS be used to reach loopbacks of routers only. This leads to a very small/fast converging IGP table. Then use iBGP to carry customer/external routes. Your IGP responds to internal path failures and your iBGP follows the path your IGP has setup. No need to rely on iBGP to detect the failure.
Your IGP would not respond as quickly if it had to carry thousands of prefixes being flooded on a state change.
iBGP communities are quite helpful categorizing prefixes and communicating cool tricks as RTBH.
March 15, 2011 at 11:02 a.m. UTC
@stretch
Example: for a large distributed enterprise network with no significant convergence time restrictions BGP would be the best choice.
Question: What considerations are really critical, when we have to choose between IGP based and BGP based network design?
I just mentioned, that problems 1-3 are not so big:
1) matter of taste, not critical
2) Path attributes are really good. On of the best BGP capabilities. Not really so complex, as it is usually described. Bestpath selection is always clear.
In contrast. EIGRP: metric is simple, but not informative, query propagation problem, etc. OSPF: nice metric, but have to think about various LSAs, hard to filter... really RFC2328 is great challenge. IS-IS: also assigns no useful metric by default.
3) Confederation. One router size subAS. No excessive recursion. I don't separate IBGP and EBGP sessions here, the protocol is always the same.
So, I'd focus on following reasons: a) convergence; b) not designed to work inside AS without IGP support (session restrictions, etc.); c) sometimes we don't need anything more powerful then IGP.
Really, I don't think that my description is better. Post content is good as always. Just want to preserve beginners from thinking that IGP vs BGP choice is simple.
The next question is usually: if OSPF, for example, is so good, why not to use it for inter AS routing? =)
And by the way, what's the real difference between IGPs and BGP, if I can use (and sometimes have to use) BGP for intra AS routing? (based on previous CCSI experience).
March 17, 2011 at 1:26 a.m. UTC
There is a dynamic BGP neighbor option. You utilize an IP Range for the neighbors along with peer groups. It does work but if you know the neighbors IP range, why not static neighbors.
March 19, 2011 at 5:42 p.m. UTC
Interesting, but I'm not sure the real use case of iBGP is taken into account and only confuses people who have networks too small to even consider iBGP. You can't rely on IGP 'internally' for extremely large networks - and iBGP fills that void because it can handle full tables in appropriate architecture placements. Consider, an even small, ISP. Say 500k customers, spanning multiple states. Do you really think behind that AS number they're going to be running one large IGP? If you think so - think again. This is where iBGP is a requirement and a security improvement as, like, IPsec - it has to be specifically configured for distribution of these large networks. People make far more mistakes and/or run inefficient (i.e. improperly configured networks) who run IGP only networks. It has to do, partially, with the fact that if it works - there's nothing wrong. I've seen misconfigurations in almost ever large corporate network I've consulted for. Things like link costs have not been appropriately accounted for over the years (really your 10G link has the same cost as those 1Gs - interesting).
Are IGPs required with IGP? Most certainly - your core concept of the fact that iBGP is a bad IGP is correct, however reading this does not lend to the usefulness of iBGP in large networks.
November 4, 2015 at 7:52 a.m. UTC
Nice explanation
March 9, 2016 at 11:36 a.m. UTC
Very glad to have come across this article, and some valid views shared thanks to all for that.
Let me first mention something before I forget, with a mixture of EGP and IGP, one often ends up with multiple of redistribution, and redistribution, if not understood intimately, can cause pain and even financial loss to any organisation.
The biggest ever drawback with OSPF is with its non-existent filtering capabilities.
Why do some of us believe a network cannot be built with just BGP, be it an small or large one.
I am currently working with a medium/large size non-mission-critical enterprise who are running OSPF as IGP and BGP to external providers. Fortunately the topology is relatively small. Networks have become 'flatter'in design over the past 7-8years since devices have become much more powerful.
In my particular case with 'flat'ish'design and low number of prefixes, I'm electing for eBGP between DCs. As you know there are a plethora of knobs to tweak paths etc for redundancy. OSPF allows for path limitations too, but with larger topologies one could run out of 'options'
Manually configuring neighbors is better in most situations, but where there are hundreds or thousands of neighbors, then perhaps not. That said some here have highlighted that in fact dynamic neighborships, if required, can be achieve with BGP.
I could go on here, but lets be straight about something. You can build a network with BGP (iBGP or eBGP) only if you wanted i.e. with no IGP.
BGP is complex but so is OSPF and so is EIGRP, and with redistribution it becomes even more challenging.
The route-recursion drawback highlighted by the author could be a concern in very large networks made up of routers that are NOT powerful and which have excessively large routing-table entries and volume traffic.
August 14, 2016 at 3:59 p.m. UTC
@Stretch: I am a beginner to BGP so pardon my ignorance. Referring to the figure in your article, let us say we want to establish IBGP between R1 & R4 (assume no IGP in network). How would that be achieved as TCP session has to be established before IBGP peering can be established and for TCP connection, don't we need IGP for end to end reachability.
September 3, 2016 at 12:33 p.m. UTC
HI Stretch,
Nice article. Does the ibgp router need to have a route to its ibgp peer in its routing table to keep the ibgp session up?
I have two routers doing ibgp with one another using loopback interfaces and even i shutdown the one router, the other router keeps the ibgp peering up until end of the timer, even though it doesnt have the route to the peer's loopback anymore. Is this normal behavior?