The premiere source of truth powering network automation. Open and extensible, trusted by thousands.
NetBox is now available as a managed cloud solution! Stop worrying about your tooling and get back to building networks.
Defending Active/Standby Failover
By stretch | Monday, March 19, 2012 at 1:17 a.m. UTC
When we discuss simple network failover solutions, we typically are contrasting two fundamental options: active/active and active/standby. These describe the manner in which two redundant devices operate under normal conditions.
In active/standby implementations, only the primary device in a pair passes traffic. The standby device sits idle, ready to assume the active role should the primary device fail. The standby device may receive routing and state information from the primary device in order to facilitate stateful failover, but it doesn't actually pass traffic until the primary device fails.
In active/active implementations, both devices are online and pass traffic under normal conditions. When one device fails, all traffic flows through the remaining device.
Customers often have a difficult time coming to terms with the perceived expense of an active/standby failover solution. The notion that one is paying double for an extra device "that doesn't do anything most of the time" clashes with the nature of a responsible consumer. In an active/active implementation, the second device is at least passing traffic, which is easier to justify psychologically. However, active/active implementations present a hidden danger: artificial scalability.
Let's examine a scenario in which an organization has implemented two Cisco ASA 5510 firewalls configured for high availability at its network perimeter. Although the initial throughput load on these firewalls is low, it is growing steadily over time. Eventually the average load creeps up to around 80%, and the network begins to experience sporadic spikes in throughput beyond the maximum load a single ASA 5510 can handle, which we'll refer to as the 100% threshold.
Consider how the two failover methods we've described will react to the increasing demand for throughput. In an active/standby implementation, the primary firewall will choke during the periods of heavy load and drop traffic. (This is not likely to trigger a failover, although even it does, the standby firewall will experience the same issue.) This provides early warning to network administrators that the network has begun outgrow the current platform and that a redesign is needed.
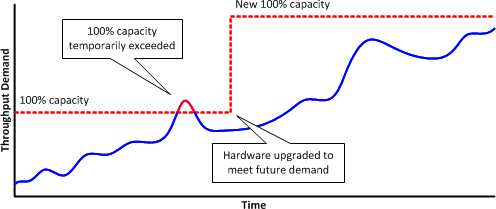
In an active/active implementation, however, the combined pair of ASA 5510s are able to handle more traffic than a single device (the 200% threshold). The active/active pair has no issue with traffic exceeding the 100% threshold and demand continues to grow so much that the average throughput is now beyond the maximum capacity of a single device. What happens when a failure occurs? The maximum capacity drops to the 100% threshold and the remaining device is unable to accommodate the full traffic load. A substantial amount of traffic is dropped until the primary device is brought back online to handle its share of the load.
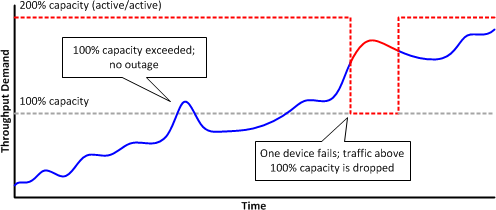
Of course, like so many potential network issues, this risk can be mitigated by diligent monitoring and reporting. But I believe it does help strengthen the case for active/standby failover when one needs to defend that idle second firewall to a particularly budget-conscious customer.
Posted in Design
Comments
March 19, 2012 at 2:33 a.m. UTC
Active/Active ASA deployments are really a pair of Active/Standby contexts. A proper configuration would have each context limited to 50% resources, so that any one ASA could handle 100% load. In essence, half your resources are still sitting their doing nothing, but both ASAs are active.
March 19, 2012 at 2:58 a.m. UTC
There's a third option: active/active with routed primary.
In this two or more devices are "active" and have NLRI knowledge of the network, but by policy only one device is preferred and actually processes traffic at a time...
We find this preferable in some cases because failing over to a standby unit sometimes results in a routing hit, causing traffic to re-route to a completely different cluster elsewhere. And thats bad.
cloudtoad
March 19, 2012 at 8:15 a.m. UTC
Not sure how Active/Active is any different from L3/GLBP load balancing in a campus LAN environment? What about the use of QoS to manage congestion during a failure condition?
March 19, 2012 at 3:40 p.m. UTC
Malbert, I would say its more like HSRP/VRRP configured to do load balancing using different groups. :)
Regarding the QoS.... A failure in an Active/Active scenario assuming that the firewalls are working at their highest capacity, QoS will not be of much help. QoS can manage the congestion upto some extent. Like say if you're using traffic shaping to shape the traffic upto a certain threshold. Traffic going beyond that threshold will be placed in the BEQ/LLQ as configured. Even a little traffic going beyond that threshold causes delay and jitter. Imagine what would be the case if an entire firewall went down and there's only one left to take over the load.
As Santinorizzo said, "A proper configuration would have each context limited to 50% resources", would be the key to overcome this kind of a situation. It might not be a very effective solution but its at least better to have something in place to minimize the effect of the failure.
@Cloudtoast, that's interesting! :) But if only one device is actually processing the traffic, how come it comes under Active/Active category?
March 19, 2012 at 4:57 p.m. UTC
This is mind easing music to my ears. My company Executives have been struggling with this concept. They could not fathom spending money on a device that is sitting there idle. Top notch info. Thanks guys!
March 19, 2012 at 8:41 p.m. UTC
Another argument against active/active setups is that you don't always know which firewall is handling what flows, so it can complicating things when troubleshooting.
March 20, 2012 at 2:15 p.m. UTC
Isn't there a problem with vpn's also?? I Think active active can't process dynamic site to site vpn's. Correct me if i'm wrong.
March 22, 2012 at 5:17 a.m. UTC
@Guest.. Yes. VPN failover is supported only in Active/Standby failover and that too only when running in single context mode.
March 22, 2012 at 8:30 a.m. UTC
This time i must disagree with Jeremy, cause in the second case the scoping is badly designed.
If you put the same failure time of the second case on the active/standby the result will be the same, will not be enough to manage that amount of traffic too, so you will need the same upgrade on twice cases.
Obviously you should have monitored the bandwith to see the overall progress and don´t wait to see a temporal overload on the active to plan an upgrade..
March 22, 2012 at 8:45 a.m. UTC
To explain it better on the first case you will be forced to upgrade twice devices for bandwith requirements, cause only one will be active for all the traffic,
and for the second case will be the same requirement needs but in this case for the bandwith rising the more time you will be covered by only one if the other fails
And all of this without seeing role/contexts, etc.., so planning a HA it´s not a trivial task to categorize only by a bandwith requirement.
March 22, 2012 at 12:17 p.m. UTC
@xfw: The difference with the active/standby design is that early peaks in throughput are enough to provide a clue that your infrastructure needs to expand without sacrificing a substantial amount of traffic, as in the case of an active/active failure.
As mentioned in the article, diligent monitoring helps avoid this issue in either case. However, determining with maximum capabilities of a device with arbitrary (and changing) features enabled is not a simple thing.
March 22, 2012 at 12:45 p.m. UTC
Both AA and AS are fine capacity-wise if your monitoring is set up properly (it is right?). The main reason to avoid AA like the plague is the convoluted mechanisms that are used get traffic going to multiple devices that are a pain to troubleshoot and often break.
March 27, 2012 at 12:33 a.m. UTC
@xfw: I think a clarification on Jeremy's plots are needed. In the first case, the "new 100% capacity" is not the addition of a secondary device, but a proper upgrade of the first. He had an upper limit (100%) and had a pike that warned the administrator, which upgraded the full equipment, both active and standby. The 100% is fully redundant. If the active fails, the standby can take the full traffic. At all time, both, the active and standby are able to take the full charge, but only the active one actually does. This gives the false sensation of wasted money.
In the second plot, the 100% line is the same, but Active/Active gives the false sensation of having double the capacity than the system actually has. Usually, in an A/A scenario you would keep the load under 100% at all times, but a spike doesn't give you any warning. In Jeremy's case, the admin doesn't notice a problem when the traffic is at 120% and never upgrades the devices. When the active fails, the real capacity "decreases" from 200% to 100%, giving the mentioned problems.
It is not to be taken literal because A/As depend on contexts, but Jeremy has a great point. The idea of "I'm wasting money on the redundancy link" is stupid. In a correctly dimensioned A/A system (not necessarily ASAs), your throughput must always stay below (N-f)/N where N = number of devices, f = amount of failed devices support wanted. In ASA A/A, N=2 and f=1. For this case, in a correctly-dimensioned system, you always must "waste" 50% of your money, be it A/A in throughput or A/S in devices.
RAID is a good example of this, too: even if parity disks are being used, it's wasted space.
March 26, 2013 at 8:34 p.m. UTC
Excellent read - I could not agree with you more.
July 18, 2013 at 6:00 a.m. UTC
Manual monitoring is not sufficient to monitor. You could have used a Load Balancer in front of the active/active pair, and let the load-balancer limit the load on each to 50%. That way, you can run an active/active without exceeding the threshold of each, to achieve a combined 100%. Once traffic starts dropping, you can simply add a 3rd node, and load-balance across all three.
And yes, load-balancers are expensive, especially, if you have redundant load-balancers.